DoorDash Announces $440,000 in Relief Grants for Restaurants Impacted by Disasters
In 2023, DoorDash has awarded relief grants to 44 restaurants in the United States, Canada, and New Zealand.
Read more
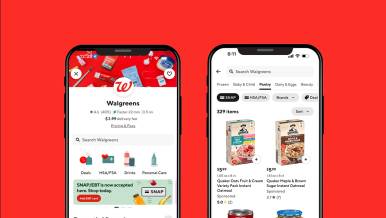
DoorDash and Walgreens Launch Unprecedented Access for SNAP Customers
DoorDash and Walgreens today announced a new collaboration to offer SNAP/EBT payment at nearly 7,800 Walgreens stores across the country.

Our Commitment to Maintaining a Safe and Trusted Platform
At DoorDash, we want every consumer, Dasher, and merchant to have a safe experience each time they use our platform.

New Data Shows Seattle’s Untested Law has Dire Consequences for Local Businesses and Dashers
Small businesses continue to lose millions in revenue as orders dry up due to extreme regulations

DoorDash Announces New Partnerships With Beloved West Coast Grocers
Vallarta Supermarkets, New Seasons Market, Haggen, Mother’s Market, and Jimbo’s join DoorDash as the platform continues to broaden non-restaurant offerings

DoorDash Available at Wakefern Food Corp. Banners
All ShopRite, Price Rite Marketplace, The Fresh Grocer, Fairway Market, Gourmet Garage, and Dearborn Market locations are now on DoorDash Marketplace
